Melakukan web scraping pada platform sebesar Instagram seringkali terasa seperti bermain kucing-kucingan dengan algoritma keamanan yang sangat canggih. Jika Anda seorang pengembang yang menggunakan Node.js, Anda mungkin sudah akrab dengan Puppeteer. Namun, tantangan terbesar muncul ketika skrip Anda tiba-tiba terhenti karena blokir IP atau akun yang terkena pembatasan. Dalam artikel ini, kita akan membahas secara mendalam mengenai cara atasi shadowban instagram web scraping node js puppeteer agar aktivitas pengambilan data Anda berjalan lancar dan aman.
Shadowban atau pembatasan akses secara diam-diam adalah mekanisme pertahanan Instagram untuk mencegah bot otomatis mengeksploitasi data mereka. Tanpa teknik yang tepat, skrip Puppeteer Anda akan dengan mudah terdeteksi sebagai aktivitas non-manusia. Mari kita bedah strategi teknis untuk melewati rintangan ini.
- Apa itu Shadowban dalam Konteks Web Scraping?
- Mengapa Puppeteer Mudah Terdeteksi oleh Instagram?
- 1. Menggunakan Puppeteer Extra Stealth Plugin
- 2. Implementasi Rotating Residential Proxy
- 3. Optimasi User-Agent dan Browser Fingerprinting
- 4. Simulasi Interaksi Manusia (Human-like Behavior)
- 5. Manajemen Cookie dan Sesi yang Efektif
- Contoh Kode Node.js Puppeteer Anti-Shadowban
- Kesimpulan dan Langkah Selanjutnya
Apa itu Shadowban dalam Konteks Web Scraping?
Dalam dunia media sosial, shadowban biasanya berarti postingan pengguna tidak muncul di hashtag atau feed orang lain. Namun, dalam konteks web scraping Node JS Puppeteer, shadowban merujuk pada kondisi di mana alamat IP atau akun yang Anda gunakan dibatasi aksesnya secara parsial.
Gejalanya bisa berupa konten yang gagal dimuat (empty response), munculnya tantangan CAPTCHA yang terus-menerus, atau pengalihan otomatis ke halaman login meskipun Anda sudah masuk. Instagram menggunakan sistem deteksi berbasis perilaku dan reputasi IP untuk menentukan apakah sebuah permintaan berasal dari browser asli atau bot otomatis.
“Keberhasilan web scraping tidak hanya ditentukan oleh kemampuan mengambil data, tetapi oleh kemampuan untuk tetap tidak terdeteksi oleh sistem keamanan target.”
Mengapa Puppeteer Mudah Terdeteksi oleh Instagram?
Secara default, Puppeteer menjalankan browser Chromium dalam mode “headless”. Browser dalam mode ini meninggalkan jejak digital (fingerprint) yang sangat jelas bagi server Instagram. Beberapa alasan mengapa skrip Anda cepat terkena shadowban meliputi:
- Navigator.webdriver: Properti ini secara otomatis disetel ke
truepada browser otomatis, memberi tahu website bahwa ini adalah bot. - Inkonsistensi WebGL: Parameter grafis pada headless browser seringkali tidak sesuai dengan perangkat asli.
- Kecepatan Eksekusi: Bot melakukan permintaan ribuan kali lebih cepat daripada manusia normal.
- IP Reputation: Menggunakan IP datacenter yang sering digunakan untuk spamming akan langsung memicu alarm keamanan Instagram.
1. Menggunakan Puppeteer Extra Stealth Plugin
Langkah pertama yang wajib dilakukan sebagai cara atasi shadowban instagram web scraping node js puppeteer adalah menggunakan plugin stealth. Plugin ini dirancang untuk menyembunyikan properti-properti yang menandakan bahwa browser dijalankan secara otomatis.
Dengan puppeteer-extra-plugin-stealth, skrip Anda akan melewati tes deteksi bot dasar seperti navigator.webdriver, chrome.runtime, dan berbagai teknik fingerprinting lainnya. Ini adalah fondasi utama agar browser Anda terlihat seperti user biasa yang sedang berselancar.
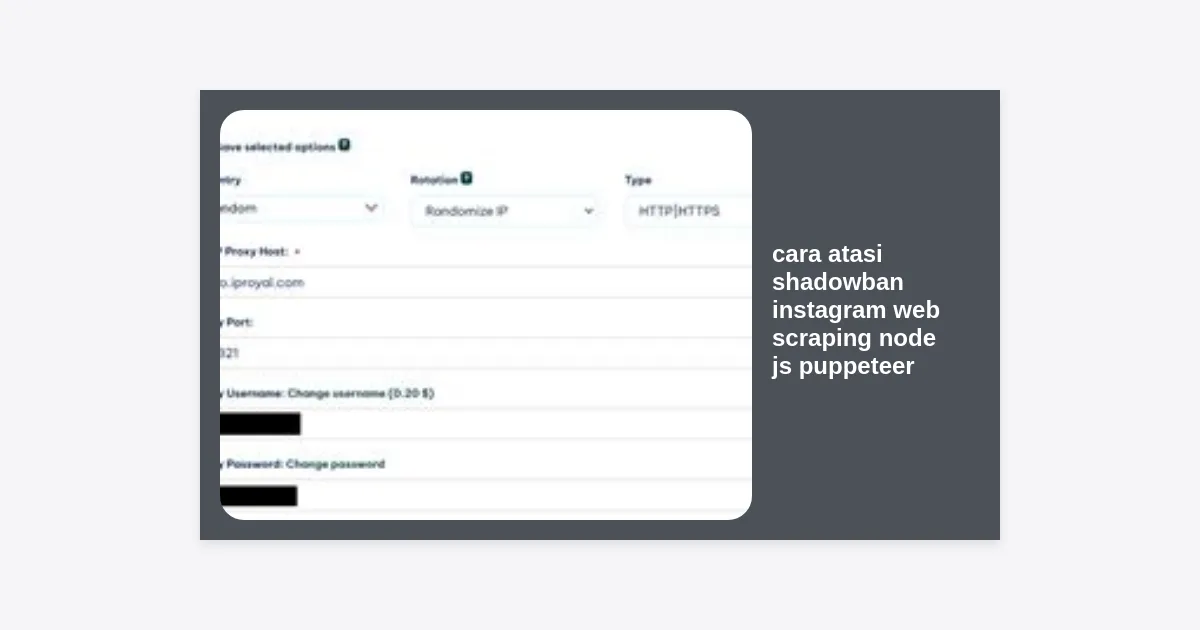
2. Implementasi Rotating Residential Proxy
Instagram sangat ketat terhadap alamat IP. Jika Anda melakukan scraping dari satu IP secara terus-menerus, shadowban adalah kepastian. Solusinya adalah menggunakan Residential Proxy. Berbeda dengan IP datacenter, IP residensial berasal dari penyedia layanan internet (ISP) rumahan, sehingga terlihat lebih organik.
Pastikan Anda menggunakan fitur rotasi proxy, di mana setiap permintaan atau setiap sesi menggunakan alamat IP yang berbeda. Hal ini mencegah pola akses yang mencurigakan dari satu lokasi yang sama dalam waktu singkat.
Tipe Proxy untuk Instagram Scraping
Berdasarkan tingkat keberhasilannya, berikut adalah urutan proxy yang disarankan:
- Mobile Proxy (4G/5G): Paling aman karena ribuan pengguna asli sering berbagi IP yang sama.
- Residential Proxy: Sangat efektif dan memiliki reputasi tinggi di mata algoritma Instagram.
- Datacenter Proxy: Murah, namun sangat berisiko tinggi terkena blokir instan.
3. Optimasi User-Agent dan Browser Fingerprinting
User-Agent adalah string yang memberi tahu server tentang tipe browser dan sistem operasi yang Anda gunakan. Menggunakan User-Agent default Puppeteer adalah kesalahan fatal. Anda harus menggunakan User-Agent dari browser populer seperti Chrome, Firefox, atau Safari versi terbaru pada Windows atau macOS.
Selain User-Agent, perhatikan juga aspek viewport. Jangan biarkan ukuran layar default Puppeteer (800×600). Setel ke resolusi standar seperti 1920×1080 untuk meniru tampilan desktop modern atau resolusi ponsel populer jika Anda menargetkan versi mobile.
4. Simulasi Interaksi Manusia (Human-like Behavior)
Algoritma anti-bot Instagram menganalisis bagaimana pengguna berinteraksi dengan halaman. Jika skrip Anda langsung menuju elemen target dan mengambil data dalam milidetik, sistem akan mendeteksinya sebagai bot. Sebagai cara atasi shadowban instagram web scraping node js puppeteer, Anda perlu menambahkan jeda acak (random delays).
Gunakan fungsi setTimeout dengan durasi yang bervariasi antara aksi. Misalnya, setelah membuka profil, tunggu 2-5 detik sebelum melakukan scroll. Simulasikan juga gerakan mouse dan scrolling yang tidak linear agar terlihat alami.
5. Manajemen Cookie dan Sesi yang Efektif
Jika scraping Anda memerlukan login, manajemen cookie menjadi sangat krusial. Jangan melakukan login setiap kali skrip dijalankan. Ini adalah perilaku yang sangat mencurigakan. Sebaliknya, simpan cookie setelah login pertama ke dalam file JSON, lalu muat kembali cookie tersebut untuk sesi berikutnya.
Dengan menggunakan cookie yang sudah ada, Anda meminimalkan frekuensi login yang bisa memicu checkpoint keamanan atau verifikasi dua langkah (2FA).
Contoh Kode Node.js Puppeteer Anti-Shadowban
Berikut adalah contoh implementasi dasar menggunakan Node.js dan Puppeteer dengan teknik stealth untuk meminimalkan risiko shadowban:
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
// Gunakan plugin stealth
puppeteer.use(StealthPlugin());
async function scrapeInstagram() {
const browser = await puppeteer.launch({
headless: true, // Gunakan false untuk debugging
args: [
'--no-sandbox',
'--disable-setuid-sandbox',
'--proxy-server=ALAMAT_PROXY_ANDA:PORT' // Opsional: Gunakan proxy
]
});
const page = await browser.newPage();
// Set User-Agent yang realistis
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36');
// Set Viewport
await page.setViewport({ width: 1366, height: 768 });
try {
console.log('Membuka halaman Instagram...');
await page.goto('https://www.instagram.com/explore/tags/teknologi/', { waitUntil: 'networkidle2' });
// Simulasi scroll manusia
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
let distance = 100;
let timer = setInterval(() => {
let scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if(totalHeight >= scrollHeight){
clearInterval(timer);
resolve();
}
}, 100 + Math.random() * 200); // Jeda acak
});
});
// Ambil data di sini
console.log('Scraping selesai tanpa terdeteksi!');
} catch (error) {
console.error('Terjadi kesalahan:', error);
} finally {
await browser.close();
}
}
scrapeInstagram();
Kesimpulan dan Langkah Selanjutnya
Mengatasi shadowban saat melakukan web scraping pada Instagram memang menantang, namun bukan tidak mungkin. Kunci utamanya terletak pada kombinasi alat yang tepat dan perilaku skrip yang menyerupai manusia. Dengan menerapkan cara atasi shadowban instagram web scraping node js puppeteer yang telah kita bahas—mulai dari penggunaan stealth plugin, rotasi proxy residensial, hingga simulasi interaksi manusia—Anda dapat meningkatkan tingkat keberhasilan scraping secara signifikan.
Selalu ingat untuk mematuhi kebijakan privasi dan ketentuan layanan platform yang Anda scrape. Gunakan data secara bertanggung jawab dan hindari melakukan scraping dengan intensitas yang dapat merusak performa server target. Selamat mencoba dan semoga proyek Node.js Puppeteer Anda sukses!
Jika Anda membutuhkan bantuan lebih lanjut dalam mengoptimalkan skrip scraping Anda, jangan ragu untuk mengeksplorasi dokumentasi resmi Puppeteer atau bergabung dengan komunitas pengembang Node.js.